Automation is being applied across just about every aspect of IT operations to increase speed and efficiency, improve availability, and foster agility and innovation. One area where automation is lagging, however, is network troubleshooting, which accounts for a as much as 65% of a NetOps engineers time according to recent studies.
Here’s a typical workflow for responding to an IT event — for example, a slow application:
- Enterprise NetOps teams typically have an event console like SolarWinds or Splunk that’s listening to the network to detect any anomalies that are occurring. Or, a user may call the help desk using a ticketing system like ServiceNow or BMC Remedy for incident management.
- The trouble ticket is then addressed by a tier 1 engineer who tries to diagnose and resolve the issue by digging through the CLIs of all the devices in the affected segment.
- If they can’t solve the problem, it is escalated to somebody with more experience. Unfortunately, since information is rarely shared, the new network engineer will do the same CLI commands to diagnose the issue, duplicating efforts.
- Then there’s the remediation: the actual change or fix, which will hopefully be documented for sharing. And finally, in an ideal world, the teams review what’s happened to see how they can do better next time during a postmortem analysis.
So, the question is, “What can we do to shift this workflow to the left?” Because as this workflow progresses and the issues escalate, the teams involved get more and more expensive.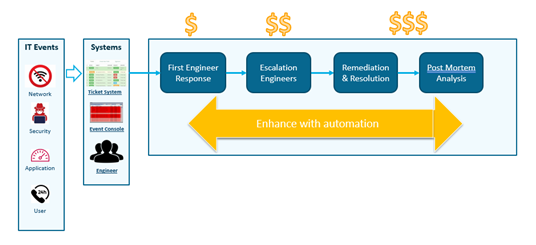
Automation provides the answers to the following questions:
- How can basic tier 1 engineering tasks be automated?
- How can first-level engineers take on more advanced troubleshooting?
- How can teams democratize lessons learned from each troubleshooting event to do better next time or even prevent issues from happening?
By applying scalable network automation, the incident response workflow can be shifted to the left – with tier 1 engineers addressing more complex issues much faster and more experienced engineers sharing their knowledge to accelerate troubleshooting while allowing them to focus on more complex network issues.
Automation is leveraged in each step of this workflow; from the moment an event is detected all the way through postmortem analysis. The goal is to reduce mean time to repair (MTTR) and make more effective use of every member of the operations teams during this response.
For more on this topic, join us at the NetBrain Webinar titled “How to Automate the Resolution of EVERY Ticket” on December 3, for more information visit
https://www.onug.net/how-to-automate-the-resolution-of-every-ticket/